If this is your first visit, be sure to
check out the FAQ by clicking the
link above. You may have to register
before you can post: click the register link above to proceed. To start viewing messages,
select the forum that you want to visit from the selection below.
Policy / Politique
The fee for tournament organizers advertising on ChessTalk is $20/event or $100/yearly unlimited for the year.
Les frais d'inscription des organisateurs de tournoi sur ChessTalk sont de 20 $/événement ou de 100 $/année illimitée.
You can etransfer to Henry Lam at chesstalkforum at gmail dot com
Transfér ŕ Henry Lam ŕ chesstalkforum@gmail.com
Dark Knight / Le Chevalier Noir
General Guidelines
---- Nous avons besoin d'un traduction français!
Some Basics
1. Under Board "Frequently Asked Questions" (FAQs) there are 3 sections dealing with General Forum Usage, User Profile Features, and Reading and Posting Messages. These deal with everything from Avatars to Your Notifications. Most general technical questions are covered there. Here is a link to the FAQs. https://forum.chesstalk.com/help
2. Consider using the SEARCH button if you are looking for information. You may find your question has already been answered in a previous thread.
3. If you've looked for an answer to a question, and not found one, then you should consider asking your question in a new thread. For example, there have already been questions and discussion regarding: how to do chess diagrams (FENs); crosstables that line up properly; and the numerous little “glitches” that every new site will have.
4. Read pinned or sticky threads, like this one, if they look important. This applies especially to newcomers.
5. Read the thread you're posting in before you post. There are a variety of ways to look at a thread. These are covered under “Display Modes”.
6. Thread titles: please provide some details in your thread title. This is useful for a number of reasons. It helps ChessTalk members to quickly skim the threads. It prevents duplication of threads. And so on.
7. Unnecessary thread proliferation (e.g., deliberately creating a new thread that duplicates existing discussion) is discouraged. Look to see if a thread on your topic may have already been started and, if so, consider adding your contribution to the pre-existing thread. However, starting new threads to explore side-issues that are not relevant to the original subject is strongly encouraged. A single thread on the Canadian Open, with hundreds of posts on multiple sub-topics, is no better than a dozen threads on the Open covering only a few topics. Use your good judgment when starting a new thread.
8. If and/or when sub-forums are created, please make sure to create threads in the proper place.
Debate
9. Give an opinion and back it up with a reason. Throwaway comments such as "Game X pwnz because my friend and I think so!" could be considered pointless at best, and inflammatory at worst.
10. Try to give your own opinions, not simply those copied and pasted from reviews or opinions of your friends.
Unacceptable behavior and warnings
11. In registering here at ChessTalk please note that the same or similar rules apply here as applied at the previous Boardhost message board. In particular, the following content is not permitted to appear in any messages:
* Racism
* Hatred
* Harassment
* Adult content
* Obscene material
* Nudity or pornography
* Material that infringes intellectual property or other proprietary rights of any party
* Material the posting of which is tortious or violates a contractual or fiduciary obligation you or we owe to another party
* Piracy, hacking, viruses, worms, or warez
* Spam
* Any illegal content
* unapproved Commercial banner advertisements or revenue-generating links
* Any link to or any images from a site containing any material outlined in these restrictions
* Any material deemed offensive or inappropriate by the Board staff
12. Users are welcome to challenge other points of view and opinions, but should do so respectfully. Personal attacks on others will not be tolerated. Posts and threads with unacceptable content can be closed or deleted altogether. Furthermore, a range of sanctions are possible - from a simple warning to a temporary or even a permanent banning from ChessTalk.
Helping to Moderate
13. 'Report' links (an exclamation mark inside a triangle) can be found in many places throughout the board. These links allow users to alert the board staff to anything which is offensive, objectionable or illegal. Please consider using this feature if the need arises.
Advice for free
14. You should exercise the same caution with Private Messages as you would with any public posting.
15. Have fun!
(Thanks to Nigel Hanrahan for writing these up!)
Reasons to believe there's FIDE rating "inflation"?
FIDE used to not publish your rating if it was under 2200. That's what is referred to as the 'rating floor' here (and in the wiki article).
Hence the example of a player going over and under the floor. The guy leaves points into the pool and can get them back from outside the pool.
How does he get them from "outside the pool"?
You are right that it is confusing to call ratings which are calculated but not published a "rating floor". And Wiki pages that propagate such nonsense need to be fixed. ;)
I think it may have confused you too, because if by "rating floor" you really mean something like "calculated but unpublicized" then your hypothesis about how such a "rating floor" could contribute to inflation cannot be correct: there is no place outside of the rating pool to collect rating points. The player who is collecting points from the unpublicized left edge of the bell curve and losing them on the published side of this so-called "rating floor" is having no effect on the system any different from from what anyone whose performances vary from one event to another. No cause for inflation there.
[collecting water in the shallow end and dumping it in the middle doesn't raise the level of the pool.... even if there is a curtain blocking our view of the shallow end :D]
The fact that FIDE didn't (used to) publish ratings below a lower limit doesn't mean that those points aren't part of the FIDE ratings pool.
There are (almost) no points outside the pool of points.
The "almost" is because, AFAIK, FIDE does sometimes award ratings for the winners of special tournaments held in places where they think there are not enough FIDE-rated players. That happens --- and could be a source of inflation if it happened a lot or if the ratings were too generous --- but it has nothing to do with a "rating floor".
I hope this means you have given up trying to use ELO ratings for a purpose for which they were not designed, and will now use Kenneth Regan's method to do your postulating whether Capablanca or Carlsen were better players.
I have to ask you about another comment you posted in this thread:
Patrick Kirby:
a specific rating can be inflated or deflated relative to other players playing in the same pool ratings as a whole can't be deflated or inflated since a rating is by definition a relative not absolute metric.
John Upper:
I though so a few weeks ago, but here's what changed my mind:
Imagine we add (or subtract) 500 rating points from everyone's rating right now. Since rating predictions work based on the difference between the ratings of the two players, they would predict just as well as they do now, but wouldn't it make sense to talk about the ratings as a whole being "inflated" or "deflated" compared to their values before we made the 500 point change?
What you are saying there implies that ELO will predict a match between players rated 1600 and 1200 exactly the same way it will predict a match between players rated 2900 and 2500. The 2900 player should expect the same result against the 2500 player as the 1600 player should expect against the 1200 player?
Is that actually true? The absolute rating difference shouldn't be the only factor: it needs to be measured against the rating of the highest rated player.
What if we fast forward to a day when the world's highest rated player is 10400? Should s/he expect, according to ELO prediction math, the same result against a 10000 player as the 1600 against the 1200?
One of the things that indicates this is a problem (if it is in fact the case with ELO predictions) is that, if you tabulated the number of draws in many Class D tournament results versus the number of draws over many elite GM tournaments, you should expect to see many more draws in the elite sections. Which means the intra-section matches should be predicted differently, even if the rating differences between players in the sections are basically the same.
Only the rushing is heard...
Onward flies the bird.
I hope this means you have given up trying to use ELO ratings for a purpose for which they were not designed, and will now use Kenneth Regan's method to do your postulating whether Capablanca or Carlsen were better players.
I don't feel constrained to use things only for the purposes they were intended. I use a hockey stick when I clean my parent's eaves troughs. :)
Capablanca didn't have a FIDE rating -- though I suppose one could be calculated retrospectively -- but the IPRs generated by the kind of computer analysis Regan does would be my preferred way to way to compare the quality of play across such a length of time.
I have to ask you about another comment you posted in this thread...
...Imagine we add (or subtract) 500 rating points from everyone's rating right now. Since rating predictions work based on the difference between the ratings of the two players, they would predict just as well as they do now,
What you are saying there implies that ELO will predict a match between players rated 1600 and 1200 exactly the same way it will predict a match between players rated 2900 and 2500. The 2900 player should expect the same result against the 2500 player as the 1600 player should expect against the 1200 player?
Is that actually true? The absolute rating difference shouldn't be the only factor...
No, I don't think it is true, because there is another relevant factor: the "K" value changes for FIDE players over 2400, making each rating point harder to get (or lose).
Once the rating difference includes players over 2400 I think you'd have to cut the difference between the players in half. So the expected outcome would be the same for 2500 vs 2700 as between a 1500 vs 1900.
For CFC ratings the K value is cut in half over 2200, which means that a player has to earn/win the equivalent of 400 points just to go from 2200 to 2400. FWIW, I think this is why so many players take so long to go from c.2150 to 2250: each time they play higher-rated players the skill difference is much greater than the rating difference suggests.
What if we fast forward to a day when the world's highest rated player is 10400? Should s/he expect, according to ELO prediction math, the same result against a 10000 player as the 1600 against the 1200?
No idea. But if a rating system stays anywhere comparable to the current one, I think a rating that high is virtually statistically impossible. Imagine what a 10000+ rated player would have to score against Houdini: if it scored only 95/100 I think would lose more points than it would gain.
One of the things that indicates this is a problem... the intra-section matches should be predicted differently, even if the rating differences between players in the sections are basically the same.
I don't understand; you'll have to explain this.
I think small rating diffs don't lead us to predict that games should be drawn, they tell us to predict that a match between players with those ratings is likely to be close. But "close" can be +5=2-5 or +1=10-1.
I think the reason we expect more decisive games among weaker players has to do with what we know about the game: the drawing margin in chess is so big to begin with, to lose you have to make either a big mistake against a competent opponent or several small ones that are exploited by excellent play by the opponent. Weak players blunder more, and most of their games are decided by big oversights that don't take great chess skill to exploit. Strong players blunder less, and make fewer weak moves, so naturally there are more draws between strong players.
No, I don't think it is true, because there is another relevant factor: the "K" value changes for FIDE players over 2400, making each rating point harder to get (or lose).
Once the rating difference includes players over 2400 I think you'd have to cut the difference between the players in half. So the expected outcome would be the same for 2500 vs 2700 as between a 1500 vs 1900.
For CFC ratings the K value is cut in half over 2200, which means that a player has to earn/win the equivalent of 400 points just to go from 2200 to 2400. FWIW, I think this is why so many players take so long to go from c.2150 to 2250: each time they play higher-rated players the skill difference is much greater than the rating difference suggests.
.
Your understanding of this is factually wrong.
a) you can see from the graph that what you say does not occur.
b) for the player's rating to to remain in equilibrium you need (disregarding draws for simplicity)
p(w)*K*points_per_win = p(l)*K*points per loss
where p(w) is the probability of winning, p(l) is the probability of loss
As the K factor appears on both sides of the equation, it clearly does not affect the probability of winning distributionn (as a function of rating difference)
expected score versus rating difference for selected rating levels:
You are right that it is confusing to call ratings which are calculated but not published a "rating floor". And Wiki pages that propagate such nonsense need to be fixed. ;)
Well, experts on rating systems (Sonas etc.) seem to imply that the rating floor has this effect. And they explain a simple way in which it might operate.
Disclaimer: I don't know exactly how FIDE used to handle, for example, games between sub- and over-2200 players. Any ratings expert out there can tell us with 100% certainty how ratings were calculated in that specific case?
And we're not even touching on the subject of sub-2400 and new players (i.e. less than 30 games played) having a higher K factor than established players.
These are inflationary measures that were arbitrarily implemented in order to alleviate the expected deflationary tendency from players turnover (i.e. players leaving the pool with a rating higher than their initial rating).
If the inflationary measures are not well calibrated with regard to the deflationary tendency of the system, inflation is to be expected.
Re: Reasons to believe there's FIDE rating "inflation"?
Originally Posted by Paul Bonham
I hope this means you have given up trying to use ELO ratings for a purpose for which they were not designed, and will now use Kenneth Regan's method to do your postulating whether Capablanca or Carlsen were better players.
I don't feel constrained to use things only for the purposes they were intended. I use a hockey stick when I clean my parent's eaves troughs. :)
Capablanca didn't have a FIDE rating -- though I suppose one could be calculated retrospectively -- but the IPRs generated by the kind of computer analysis Regan does would be my preferred way to way to compare the quality of play across such a length of time.
Of course many things can be used for tasks they weren't designed for... and this is nothing personal, but with statistical methods, one needs to be very careful because misuse can lead to such things as genocide. People like to be able to use statistics to "prove" things that are nothing more than myths or racist / sexist beliefs. Since chess relates closely in most people's minds to IQ, it is an area where we should emphatically guard against misusing statistical methods. Capice?
It seems that Kenneth Regan's IPR system is actually designed for this purpose of objectively comparing any two players over any time span, so I don't have such qualms about it being used for this... although I would still tend to call its results a hypothesis.
No, I don't think it is true, because there is another relevant factor: the "K" value changes for FIDE players over 2400, making each rating point harder to get (or lose).
Once the rating difference includes players over 2400 I think you'd have to cut the difference between the players in half. So the expected outcome would be the same for 2500 vs 2700 as between a 1500 vs 1900.
For CFC ratings the K value is cut in half over 2200, which means that a player has to earn/win the equivalent of 400 points just to go from 2200 to 2400. FWIW, I think this is why so many players take so long to go from c.2150 to 2250: each time they play higher-rated players the skill difference is much greater than the rating difference suggests.
This use of the K factor seems to be very arbritary. I wonder if there is a way it could be made more precise, more linear, by comparing the absolute rating difference of the two players involved to the absolute rating of the highest rated player.
Originally Posted by Paul Bonham
What if we fast forward to a day when the world's highest rated player is 10400? Should s/he expect, according to ELO prediction math, the same result against a 10000 player as the 1600 against the 1200?
No idea. But if a rating system stays anywhere comparable to the current one, I think a rating that high is virtually statistically impossible. Imagine what a 10000+ rated player would have to score against Houdini: if it scored only 95/100 I think would lose more points than it would gain.
I think Mathieu Cloutier linked to something that said since 1985 FIDE ratings have had X amount of inflation, so if we extrapolate that out far enough, and grow the base of players big enough, can't an ELO rating reach some arbritrarily large number? Anyway, just how big that number can get isn't important. It's the fact that as the absolute ratings of the two players involved get larger and larger, their rating difference (let's denote that as RD) becomes a smaller and smaller percentage of their overall rating. That SHOULD mean their 100-game match should be closer than a 100-game match between two other players whose RD is the same but whose absolute overall ratings are much much smaller.
Again, the skill difference between a 10400 and a 10000 should be much much smaller than the skill difference between a 1600 and a 1200.
I think small rating diffs don't lead us to predict that games should be drawn, they tell us to predict that a match between players with those ratings is likely to be close. But "close" can be +5=2-5 or +1=10-1.
I think the reason we expect more decisive games among weaker players has to do with what we know about the game: the drawing margin in chess is so big to begin with, to lose you have to make either a big mistake against a competent opponent or several small ones that are exploited by excellent play by the opponent. Weak players blunder more, and most of their games are decided by big oversights that don't take great chess skill to exploit. Strong players blunder less, and make fewer weak moves, so naturally there are more draws between strong players.
Let's go with that last statement. Strong players blunder less, make fewer weaker moves. Can we not imagine then a day when the strongest players (or engines) will never blunder, will make only the tiniest of inaccuracies? Even to the point where in a multi RR between a group of them that are all this strong, all games would be drawn?
With all games drawn, the ELO predictions are garbage. There might be a 100-point ELO difference between the weakest and strongest engines in this group, so ELO says to expect the highest rated to finish N points ahead of the lowest rated. But the skill level is of such great strength that the ELO predictions no longer apply.
The ELO predictions might apply for a much lower overall strength field where draws are at a minimum, maybe even none at all. But if you have no draws at all, you have more volatility in the results, so that the 100-point spread becomes much more pertinent (for the sake of this argument, I'm assuming all of these lower-rated players are longsuffering chess adults, not fast-rising juniors). Where ELO predicts again an N-point difference between the highest and lowest rated, you could easily see a double that or more. Again, the skill level is such weak strength that the ELO predictions again don't (consistently) apply.
The K factor you mention may help with this at the lower-rated end (or not, I really don't know), but can the K factor account for the super-elite section of drawmasters? And again, it seems the K factor needs to be more linear, predicated on the absolute ratings of the two players in a contest.
The point about draws is that, as sections get stronger and stronger, there are more draws, thus the point range between highest and lowest finisher in the section tends to shrink. It seems that ELO predictions don't account for this, other than this K factor and I'm not even sure that does it.
Only the rushing is heard...
Onward flies the bird.
[I]Originally Posted by Paul Bonham
Of course many things can be used for tasks they weren't designed for... and this is nothing personal, but with statistical methods, one needs to be very careful because misuse can lead to such things as genocide. People like to be able to use statistics to "prove" things that are nothing more than myths or racist / sexist beliefs. Since chess relates closely in most people's minds to IQ, it is an area where we should emphatically guard against misusing statistical methods. Capice?
I thought that's what you were implying in a previous post, and thought it was so ridiculous that I didn't bother replying.
One problem with misusing the racist/genocide/Nazi card is that it encourages people to think you have no sense of proportion.
Of course many things can be used for tasks they weren't designed for... and this is nothing personal, but with statistical methods, one needs to be very careful because misuse can lead to such things as genocide. People like to be able to use statistics to "prove" things that are nothing more than myths or racist / sexist beliefs. Since chess relates closely in most people's minds to IQ, it is an area where we should emphatically guard against misusing statistical methods. Capice?
I would just add that IQ itself is something of questionable value. The very idea of intelligence as a linear variable that we can have more or less of, like water in a cup, has been subject to withering criticism in addition to the kinds of exposure of the racist ideology behind it by such authors as Stephen Jay Gould in The Mismeasure of Man.
Howard Gardner, among teachers for example, uses the concept of "multiple intelligence(s)" and very convincingly too.
Anyway, carry on.
Last edited by Nigel Hanrahan; Sunday, 24th February, 2013, 02:11 AM.
Reason: add links to SJG book on Wiki and Gardner's Multiple Intelligences
Dogs will bark, but the caravan of chess moves on.
I thought that's what you were implying in a previous post, and thought it was so ridiculous that I didn't bother replying.
One problem with misusing the racist/genocide/Nazi card is that it encourages people to think you have no sense of proportion.
*plonk*
Are you so dense as to think I'm accusing you of being racist? Look back and see that I was and still am sure that you are not trying to do anything more that your stated intentions, comparing chess greats from different eras. The only thing I accuse you of is misusing the ELO rating system, which now you are not doing because you've been made aware of Regan's IPR system.
On the other hand, if you are even MORE dense and think no one could or would ever misuse statistical methods in a racist / sexist fashion, then you are one of those doomed to repeat history having never learned it.
And because of an overemotional reaction, you fail to address some pertinent points raised about the ELO system.
Having thought on this more, I am wondering if the problem isn't ELO, but is the fact that chess has draws. ELO is apparently used in other sports, including football, basketball, baseball, tennis. Seems like none of those have draws (except the rare tie football game).
Is the real problem that ELO cannot be correctly applied for a game that is pure skill (no luck) and that thus has high number of draws at the most skilled levels? A game that is progressing (however slowly) to an eventual zenith of nothing but draws among it's most skilled practioners?
In fact, I think I have answered the infamous question of whether or not chess is a sport. The answer is no, because:
There is no sport for which all play is approaching absolutely predictable results.
Only the rushing is heard...
Onward flies the bird.
Your understanding of this is factually wrong.
a) you can see from the graph that what you say does not occur.
I'm not sure your graph does show that what I say does not occur (though I might be too tired to be thinking clearly here, and it's a bit hard for me to distinguish the colours on the graph on my monitor). But...
Assuming the x-axis is: (player rating) - (opponent's rating).
The differences aren't as big as I would have expected, but it looks like the 2400+ players actually score a bit better than the other three groups when they out-rate their opponents (left side of the graph), and score a bit worse than the other three groups when they are outrated by their opponents (right side of the graph). That's exactly what I'd expect to see given that CFC rating points over 2200 are in a sense twice as hard to get.
If I'm reading it right, the purple 2400+ line being (mostly) above the other players' on the left side and (mostly) below on the right side actually supports my earlier hypothesis. It's not strong support, but it looks more like confirmation than disconfirmation.
Or have I just misread the chart? (if so, could you explain?)
Maybe a more detailed chart would help.
Do you have data for 2000s and 2300s and 2500s too? It might be more useful for this discussion than the data from 600 or 1200-rated players, who (I would expect) are improving so fast (and mostly playing opponents who are improving so fast) that their results are not indicative of players whose ratings have stablized at that level.
Last edited by John Upper; Sunday, 24th February, 2013, 04:19 AM.
I'm not sure your graph does show that what I say does not occur (though I might be too tired to be thinking clearly here, and it's a bit hard for me to distinguish the colours on the graph on my monitor). But...
Assuming the x-axis is: (player rating) - (opponent's rating).
The differences aren't as big as I would have expected, but it looks like the 2400+ players actually score a bit better than the other three groups when they out-rate their opponents (left side of the graph), and score a bit worse than the other three groups when they are outrated by their opponents (right side of the graph). That's exactly what I'd expect to see given that CFC rating points over 2200 are in a sense twice as hard to get.
If I'm reading it right, the purple 2400+ line being (mostly) above the other players' on the left side and (mostly) below on the right side actually supports my earlier hypothesis. It's not strong support, but it looks more like confirmation than disconfirmation.
Or have I just misread the chart? (if so, could you explain?)
Maybe a more detailed chart would help.
Do you have data for 2000s and 2300s and 2500s too? It might be more useful for this discussion than the data from 600 or 1200-rated players, who (I would expect) are improving so fast (and mostly playing opponents who are improving so fast) that their results are not indicative of players whose ratings have stablized at that level.
1) your initial starting piont was that the expected results curve for players over 2200 was scaled by 2 because of the K factor. That is quite clearly not true, both empirically (the graph) or theoreticaly.
2) You are now suggesting that the expected results curve (as a function of rating difference) might differ by smaller amounts than a factor of 2 for different rating levels. That's fine - after all, that's why I originally plotted the data - to see if that might be true. Just be clear that a) the K factor changing does not contribute to the shape of the expected results curve and b) the theory underlying the rating system is that they are identical.
3) The null hypothesis has to be (as the theory) that the curves are the same. The null hypothesis is not disproved by the data. (and of course, part of the problem is that there is insufficient data to keep the noise down). If the null hypothesis is not disproved for the results between a 1200 player playing a 800 rated player compared to a 2400 rated player playing a 1900 rated player I see no point in looking at the curves for 2100, 2200, 2300 2500 players.
4) More to the point, the null hypothesis that the expected result curve is that of theory is disproved - that is not clear from the graph I showed in the previous post - it is clear from the aggregate data graph below. If you want further discussion of that data see: http://www.victoriachess.com/cfc/opponents2.php
Personaly, I'm amazed that a game between a 1200 player and an 800 player which probably takes 15 minutes and consists of the 1200 player taking all the 800 player's pieces does have the same expected result as between a 2400 player and a 1900 player - which will probably take 3 hours or more (and the 1900 player probably thinks he is playing well and challenging the 2400 player). But that is the underlying basis of the rating system.
Last edited by Roger Patterson; Sunday, 24th February, 2013, 05:12 PM.
Personaly, I'm amazed that a game between a 1200 player and an 800 player which probably takes 15 minutes and consists of the 1200 player taking all the 800 player's pieces does have the same expected result as between a 2400 player and a 1900 player - which will probably take 3 hours or more (and the 1900 player probably thinks he is playing well and challenging the 2400 player). But that is the underlying basis of the rating system.
Actually, I think that it makes perfect sense, given that this is what the ratings are based on by definition. Thanks to how most tournaments are structured, most of the games are between people of similar strengths, so the people near one another in ratings interact the most, so ratings rapidly conform locally to match the system.
What rarely happens is an 800 player playing the 2400 player, so there is little interaction to normalize the results as a whole. Perhaps this explains the greater discrepancies in the results at more extreme rating differences.
 Tweet
Tweet
 How does he get them from "outside the pool"?
How does he get them from "outside the pool"? 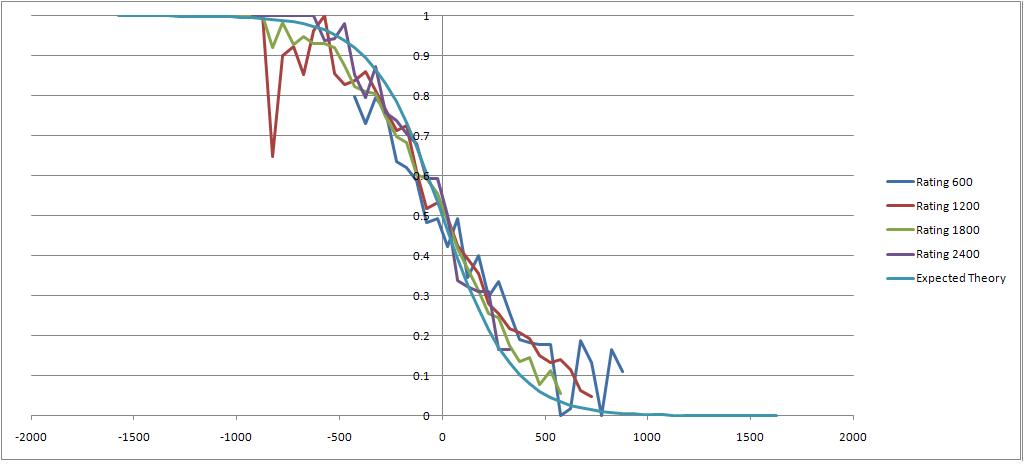

Comment